AI Overview
RAG pipelines in Ruby on Rails applications combine real time data retrieval with AI generation to deliver accurate and context aware responses. This approach helps build intelligent systems that adapt to user queries and provide reliable outputs.
Why RAG Pipelines Matter in Rails Systems
Modern applications require responses that are grounded in real time data rather than static model outputs. Traditional AI systems often rely on pre trained knowledge, which limits their ability to handle dynamic and domain specific queries.
RAG (Retrieval Augmented Generation) introduces a structured approach where systems retrieve relevant data before generating responses. Within a Rails environment, this enables applications to deliver accurate, context aware outputs without depending solely on model memory.
A skilled ruby on rails development team can design architectures where retrieval and generation layers are cleanly separated, ensuring scalability and maintainability.
This approach improves:
- Accuracy of responses
- Relevance based on live data
- Alignment with user intent
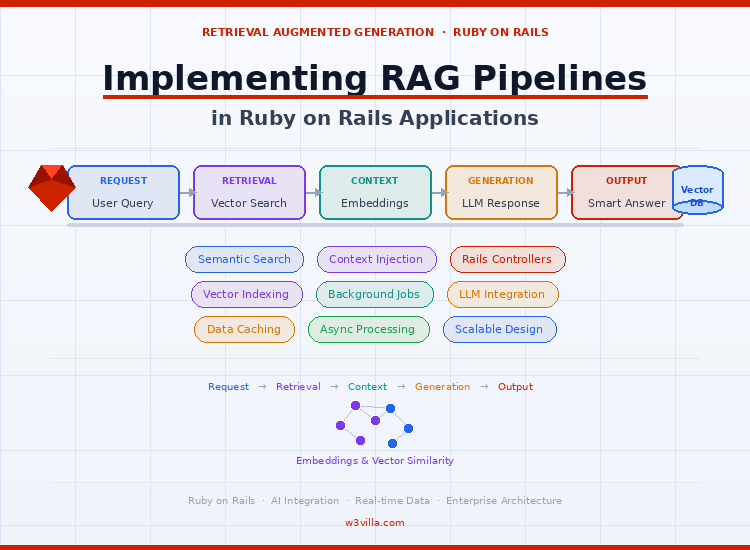
RAG Pipeline Flow: Request → Retrieval → Context Injection → Generation
A RAG pipeline is a multi stage workflow where each step contributes to the final output quality. Instead of a single AI call, the system processes data through multiple layers.
The flow typically includes:
- Receiving the user query through Rails controllers
- Retrieving relevant data from internal or external sources
- Injecting filtered context into the AI model
- Generating a structured response
This layered flow ensures that responses are grounded in actual data rather than assumptions.
Backend Orchestration: Rails as the Control Layer
Ruby on Rails acts as the central coordination layer in a RAG system. It manages how data moves between retrieval systems, AI services, and application logic.
With ror development services, Rails applications can:
- Handle API communication with AI providers
- Manage background processing for heavy operations
- Maintain structured data flow across components
Experienced ruby on rails programmers ensure that business logic remains independent from AI processing, preventing tight coupling and improving system flexibility.
Retrieval Layer Design: Structured and Semantic Search
The retrieval layer plays a critical role in determining the quality of the final output. It must efficiently fetch relevant information based on user queries.
A well designed retrieval system includes:
- Structured queries for precise data access
- Semantic search for contextual matching
- Integration with multiple data sources
Poor retrieval directly affects response accuracy, making this layer one of the most important parts of the pipeline.
Context Processing: Embeddings and Relevance Filtering
Once data is retrieved, it needs to be processed into a form that AI models can understand. This step ensures that only relevant information is passed forward.
Key operations include:
- Converting text into embeddings
- Ranking results based on similarity
- Removing irrelevant or redundant data
This stage improves response quality by ensuring that the model receives clean and focused context.
Generation Layer: Context Aware Response Construction
The generation layer uses the processed context to produce meaningful outputs. Unlike traditional AI responses, this layer relies on retrieved data to ensure accuracy.
It is responsible for:
- Producing structured answers
- Summarizing retrieved content
- Generating context based insights
For instance, in a documentation system, the model generates concise answers based only on retrieved documents rather than generic knowledge.
Async Processing Strategy: Managing Latency and Load
RAG pipelines introduce additional processing steps, which can increase latency if handled synchronously. Rails provides strong support for asynchronous execution to address this challenge.
To maintain performance:
- Background jobs handle retrieval and AI processing
- Frequently used responses are cached
- API requests are optimized and controlled
This ensures that the system remains responsive even under heavy load.
Implementation Blueprint: Integrating RAG into Rails
Implementing RAG pipelines requires a structured approach focused on system design and scalability.
Key Steps:
- Define a clear use case for retrieval based intelligence
- Prepare and organize data sources
- Implement retrieval logic (structured + semantic)
- Integrate AI services for response generation
- Optimize performance using caching and background jobs
A reliable development company ensures that each layer is modular and independently scalable.
Use Case Mapping: Applying RAG Across Applications
RAG pipelines enhance various types of applications by improving how information is accessed and presented.
They are commonly used in:
- Knowledge systems for direct answer retrieval
- Support platforms for automated responses
- Data analysis tools for summarizing large datasets
- Content systems for context aware generation
Companies like W3Villa Technologies are adopting these architectures to build intelligent and scalable applications.
Performance Optimization: Scaling RAG in Production
Scaling RAG pipelines requires careful optimization of each component. Rails provides flexibility to manage performance at different layers.
Best Practices:
- Cache high frequency queries
- Use background workers for processing
- Optimize database indexing
- Reduce redundant API calls
With proper rails development services, applications can maintain performance while handling complex AI workflows.
Conclusion
RAG pipelines in Ruby on Rails enable applications to deliver accurate and context aware responses by combining real time data with AI generation. Contact us to explore how these intelligent systems can be implemented effectively. The focus should be on building architectures where data and AI work seamlessly together for better outcomes.







